Thought of preparing a small blog related to Kafka while going through the video sessions of Gwen Shapira and Stephane Marek.
Kafka is a distributed, partitioned, replicated commit log service.
a messaging system, so how different is this from others [Active MQ, ..,]
Producers write data to Kafka and consumers read data from Kafka.
producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:

Kafka provides a fast, distributed, highly scalable, highly available publish-subscribe messaging system.
It solves much harder problem:
- communication and integration between components of large software systems.
What's unique about Kafka?
What do we do with Kafka?
The Basics
Topics, Partitions and Logs


A Topic can have multiple partitions,
 If we have more data in a topic and if you want to have data in more than one machine,
If we have more data in a topic and if you want to have data in more than one machine,
then you partition the topic into multiple partitions and put each partition in a separate machine which allows the flexibility of more memory, disk space, etc.,
Consumers can also be parallelised, it can have multiple consumers reading the same topic and each reading a different partition, which allows more throughput of the system.
Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.
Each Partition is a Log

Each Broker[Node] has many partitions

Here, the topic is split into 3 partitions, one partition in each node [orange].
Each partition has multiple replicas [exact copies in other 2 nodes/brokers] in the cluster, this will ensure high availability.
The orange one is the leader, where all the read/writes will happen and other 2 [Blue] are replicas/followers where producers and consumers never interact with it. so the leader replicates the followers.
Followers will acknowledge to the leader.

Producers will load balance and are free to write to any leader partitions.


Producers




Producer Batching



High Throughput Producer
Consumers
Consumers get data from topics in partitions

We can have consumers groups [set of consumers which are subscribed to the topic].
Each consumer in the group will fetch part of the data.
In the above example, C1 will get data from P0 and P3 and C2 will get data from P1,P2
So each consumer will get different sets of data, so there are no duplicates.
This allows more scaling.











 from Kafka > v0.10 the offsets are stored in the topics.
from Kafka > v0.10 the offsets are stored in the topics.



Kafka is a distributed, partitioned, replicated commit log service.
a messaging system, so how different is this from others [Active MQ, ..,]
Producers write data to Kafka and consumers read data from Kafka.
producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:

Kafka provides a fast, distributed, highly scalable, highly available publish-subscribe messaging system.
It solves much harder problem:
- communication and integration between components of large software systems.
What's unique about Kafka?
- Large number of consumers
- Ad-hoc consumers
- Batch consumers
- Automatic recovery from broker failure
What do we do with Kafka?
- Messaging - communicating between apps
- Website Activity Tracking (clicks, searches...)
- Metrics collection - instead of writing to logs
- Audit
- Source and target of stream processing
The Basics
- Messages are organised into topics
- Producers push messages
- Consumers pull messages
- Kafka runs in a cluster. Nodes are called brokers.
Topics, Partitions and Logs


A Topic can have multiple partitions,

then you partition the topic into multiple partitions and put each partition in a separate machine which allows the flexibility of more memory, disk space, etc.,
Consumers can also be parallelised, it can have multiple consumers reading the same topic and each reading a different partition, which allows more throughput of the system.
Each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition.
Each Partition is a Log
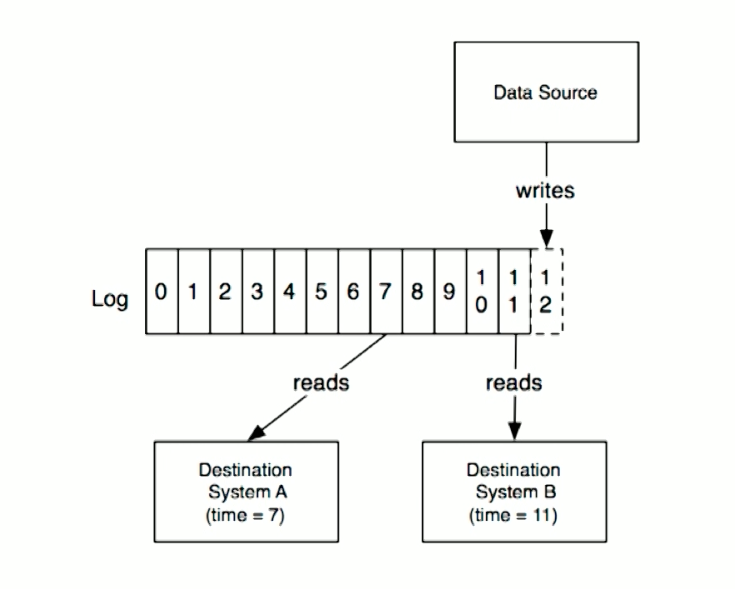
The Kafka cluster retains all published
messages—whether or not they have been consumed—for a configurable period of
time. For example if the log retention is set to two days, then for the two
days after a message is published it is available for consumption, after which
it will be discarded to free up space. Kafka's performance is effectively
constant with respect to data size so retaining lots of data is not a problem.
Each Broker[Node] has many partitions

Here, the topic is split into 3 partitions, one partition in each node [orange].
Each partition has multiple replicas [exact copies in other 2 nodes/brokers] in the cluster, this will ensure high availability.
The orange one is the leader, where all the read/writes will happen and other 2 [Blue] are replicas/followers where producers and consumers never interact with it. so the leader replicates the followers.
Followers will acknowledge to the leader.

Producers will load balance and are free to write to any leader partitions.


Producers




//create safe producerproperties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");properties.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
Producer Batching



High Throughput Producer
// high throughput producer ( at the expense of a bit of latency and cpu usage)properties.setProperty(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "20"); // 20 ms lagproperties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, Integer.toString(32*1024)); // 32 KB batch size
Consumers
Consumers get data from topics in partitions

We can have consumers groups [set of consumers which are subscribed to the topic].
Each consumer in the group will fetch part of the data.
In the above example, C1 will get data from P0 and P3 and C2 will get data from P1,P2
So each consumer will get different sets of data, so there are no duplicates.
This allows more scaling.














