Hadoop Ecosystem
HDFS - Hadoop Distributed File System
YARN - Yet Another Resource Negotiator

It's an Ecosystem of applications each having their unique role in moving, storing, and computing data.
Sqoop, Flume, Avro
Use to import and export the data depending on what kind of data it is.
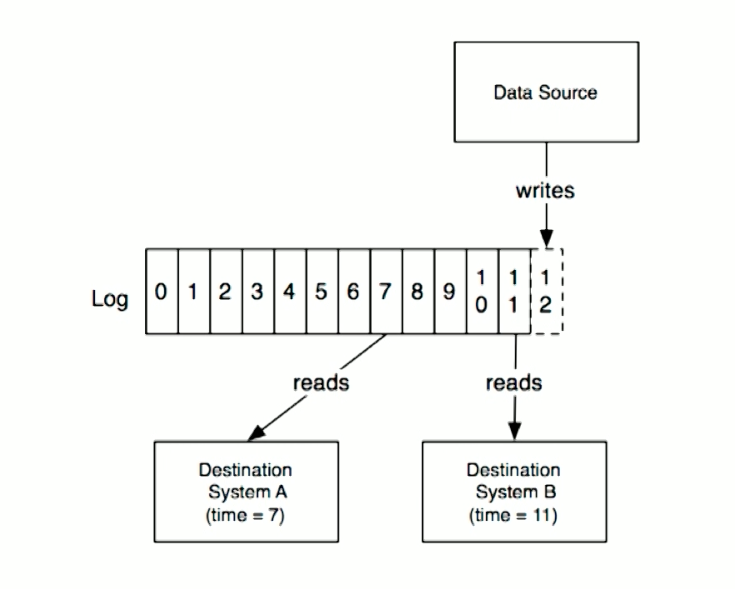
HDFS [Hadoop Distributed File System]
- data get store in HDFS
MapReduce -
-is a standard computation engine for hadoop, which is how we make calculations on data and manipulate it.
O0zie
-is used schedule jobs for completion
HDFS
- file system for Hadoop
- spans all nodes in a cluster
-stores data in 64Meg chunks on multiple servers
YARN
-controls access to cluster resources
-new in Hadoop v2
-allows multiple compute engines to run (MapReduce, Spark, Tez, so on)

Sqoop [SQl on hadOOP]
- a tool for retrieving data from databases
- pulls data from relational databases
- stores on HDFS or imports data directly to a table in Hive
- uses drivers which we need to download as per the database we use.

Flume - a tool for pulling a constant stream of data
- used to import streaming data (server logs, tweets, and so on)
- only a transport agent
- Buffered
- 3 parts:
Source - that accepts the data
Channel - that temporarily stores it
Sink - pulls the data from channel and writes it to HDFS or some other destination

MapReduce -
-is a standard computation engine for hadoop, which is how we make calculations on data and manipulate it.
- contains 2 phases: Map phase and Reduce phase

In Java program,
Map phase - "Tokenize" words, create key/value pairs
Reduce phase - Sum instances of each word from all line; creating new key/value pairs
Pig - scripting language for hadoop - alternative to java
- is a Dataflow scripting language
- Builds MapReduce programs from scripts
- User Definable Functions [UDFs]
Hive
- Data warehousing solution for Hadoop
- Uses tables, just like a traditional database
- HiveQL - SQL-ish query language
- Schema on load
- Uses MapReduce as engine
HDFS - Hadoop Distributed File System
YARN - Yet Another Resource Negotiator

It's an Ecosystem of applications each having their unique role in moving, storing, and computing data.
Sqoop, Flume, Avro
Use to import and export the data depending on what kind of data it is.
HDFS [Hadoop Distributed File System]
- data get store in HDFS
MapReduce -
-is a standard computation engine for hadoop, which is how we make calculations on data and manipulate it.
O0zie
-is used schedule jobs for completion
HDFS
- file system for Hadoop
- spans all nodes in a cluster
-stores data in 64Meg chunks on multiple servers
YARN
-controls access to cluster resources
-new in Hadoop v2
-allows multiple compute engines to run (MapReduce, Spark, Tez, so on)

Sqoop [SQl on hadOOP]
- a tool for retrieving data from databases
- pulls data from relational databases
- stores on HDFS or imports data directly to a table in Hive
- uses drivers which we need to download as per the database we use.

Flume - a tool for pulling a constant stream of data
- used to import streaming data (server logs, tweets, and so on)
- only a transport agent
- Buffered
- 3 parts:
Source - that accepts the data
Channel - that temporarily stores it
Sink - pulls the data from channel and writes it to HDFS or some other destination

MapReduce -
-is a standard computation engine for hadoop, which is how we make calculations on data and manipulate it.
- contains 2 phases: Map phase and Reduce phase

In Java program,
Map phase - "Tokenize" words, create key/value pairs
Reduce phase - Sum instances of each word from all line; creating new key/value pairs
Pig - scripting language for hadoop - alternative to java
- is a Dataflow scripting language
- Builds MapReduce programs from scripts
- User Definable Functions [UDFs]
Hive
- Data warehousing solution for Hadoop
- Uses tables, just like a traditional database
- HiveQL - SQL-ish query language
- Schema on load
- Uses MapReduce as engine